0 引言
还记得通常在MCU驱动LCD,OLED是怎样显示汉字的吗?采用取字模工具,生成字模数组,然后要显示某个字符,直接索引这个字符的数组,然后对这个数组数据进行显示就行了,就像这样: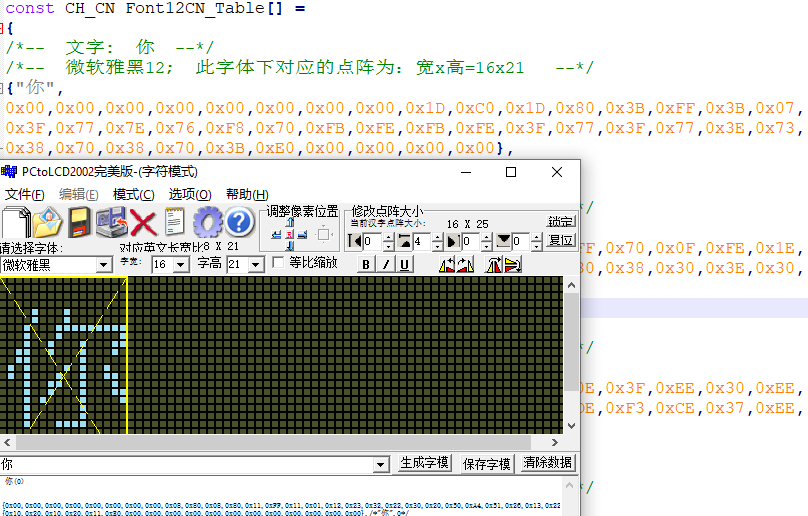
最近有开发一个物联网项目,将网络端的发过来的汉字显示到屏幕上,但问题来了,我还不知道网络端要发送具体哪些汉字,我是无法对具体的汉字取模,因此,得想办法先对所有汉字进行取模,或使用字库,于是就有了下文。
1 字符编码
先从字符编码说起:参考阮一峰博客字符编码
- ASCII码:一共规定了128个字符的编码,这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
- 非ASCII码:英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。
- GB2312,GBK,Unicode,UTF-8均为非ASCII编码
- Unicode码:如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
- 注意:Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储
- UTF-8码:UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式,是Unicode 的实现方式之一。
- GB2312,GBK:GB2312是常用汉字的专用编码,GBK是所有汉字的专用编码。
- 注意:GB类的汉字编码与后文的 Unicode 和 UTF-8 是毫无关系的
2 液晶屏汉字显示原理
- ASCII字符显示,由于ASCII字符仅128个,可以实现对每个字符一一取模,且占用MCU的RAM不会过大,此处不再介绍ASCII字符的显示。
- 为什么显示英文一般不用字库芯片?
英文的单词都是由26个字母构成了,加上大小写的区别和其它一些字符,也不过才95个。假如要显示8 * 16像素大小的字符,每一个字符需要16个字节的字库空间,95个字符即是95 * 16=570个字节。即占用570个字节的RAM。对于小型MCU几K字节的RAM来说,绰绰有余了。
- 为什么显示中文需要字库芯片?
显示中文的话,需要每一个字的字模,16*16像素大小的中文,每一个中文都要32个字节。GBK收录了中文两万多个,如果要都能显示,需要700多K字节的空间。所以,我们选择了把这些字库放在外部存储器当中,可选择2M的FLASH存储芯片W25Q16做为存储媒介。放个700多K的字库足够了,并且,同时放两种字体的字库都没问题。
- 常规汉字显示,采用相关的汉字取字模工具(PCtoLCD2002完美版),取出字模,相关参数设置如下所示:

由于我采用的液晶屏是逐行显示的,不同的液晶屏采用不同的显示模式,需根据具体情况选择字模。
取出“你”字模后,将字模数据复制到notepad++,调整成设置好的16列,21行的样式,在将16进制数据转换成2进制数据,然后将0替换成空格,即可找出汉字“你”的原型。

- 对于液晶屏而言,字符,图片的显示都是像素点的点阵显示,因此,只要将上述数组中的数据转换成点阵数据显示到液晶屏中即可,对于二进制位1的位数据,显示出该像素点,对于二进制位0的位数据,不显示该像素点,即可显示出该汉字(暂不考虑颜色显示)。
3 字符显示的实现
上面讲到了字符显示的原理,接下来将讲解字符显示的实现,相关代码不依赖于底层,具有很好的移植性,且在文章最后放出了Github链接,要实现该代码的功能,需要以下前提条件:
- 已经在液晶屏上实现了画点功能,该函数将直接调用该功能
- 液晶屏在显示时,逐行扫描,且需要高位在前(参考上一节相关参数设置,其它类型的屏幕可能有所不同)
注:由于代码过长,为不影响阅读,仅放部分关键代码,如有需求,更多请参考文末的Github
for (j = 0; j < font->Height; j++) {
for (i = 0; i < font->Width; i++) {
if (*ptr & (0x80 >> (i % 8))) {
Paint_SetPixel(x + i, y + j, Color_Foreground);
} else {
Paint_SetPixel(x + i, y + j, Color_Background);
}
if (i % 8 == 7) {
ptr++;
}
}
if (font->Width % 8 != 0) {
ptr++;
}
}此代码简单地实现了索引字模数组中的一个unsigned char类型的元素中的8位,将该8位绘制成像素点,此为字符显示的基本实现,
4 任意汉字显示的实现(采用取模法)
本节将讲述如何实现任意汉字的显示。
需要准备以下工具:
- GBK字库
- 取模软件
- 二进制文件生成工具
如下图所示,且相关工具可从文末Github中直接获取得:
具体操作步骤如下:
- 将字库取模
在工具栏处点“打开”按钮,打开gbk_ziku.txt文件,然后根据自己的需要,设置想要的取模方式,然后点工具栏上的“输出”按钮 并等待其完成,完成后会在取模软件所在路径生成了一个temp.txt文件。现在我是按照“宋体、点阵数为16、字重为4、取模为为16*16、对齐设置为左上、方向设置为横向取模,高位在左”的方式来取的字模,也就是我平时TFT液晶屏常用的一种字模。
打开temp.txt文件可知, 该文件包含了所有字库的点阵,且采用GBK编码排序:
- 将取模的文件生成二进制文件
将该temp.txt文件转换为二进制文件,供程序读取。在windows下进入CMD命令控制台,进入到相关文件所在的路径,接着,执行命令ziku.exe temp.txt命令,执行效果如下图所示,执行后将生成一个ziku.bin的文件:

- 将二进制文件存入外部Flash,或Linux系统用户文件夹下:
得到ziku.bin文件后,可将该字库二进制文件存入外部Flash如W25Q16中(MCU),或者Linux系统用户文件夹下(Linux);其中,将该bin文件存放如外部Flash的方法为:
- 单片机与电脑采用串口连接,单片机与W25Q16采用SPI方式连接。所以,我们只需要给单片机写一个接收串口数据再把数据通过SPI口传输到W25Q16中的程序即可。
- 使用FT232H芯片工具,该工具实现了USB转SPI,USB转I2C的功能,可直接通过PC的USB接口下载到带I2C或SPI接口的Flash或E2PROM中。
- 检验二进制文件的可用性
本文将只在Linux系统下进行检验,MCU环境下的检验同理:
该bin文件的检验程序如下所示(相关程序均已上传文章末尾的Github):
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdint.h>
#include <unistd.h>
#include <stdlib.h>
void Get_GBK_DZK(uint8_t *code);
FILE *fd;
int main(void){
//字库所在目录
if(NULL == (fd=fopen("./ziku.bin","rb"))){
printf("Open dir error\r\n");
}
Get_GBK_DZK("你");
printf("\r\n");
Get_GBK_DZK("好");
printf("\r\n");
Get_GBK_DZK("!");
fclose(fd);
}
//得到字模
void Get_GBK_DZK(uint8_t *code){
uint8_t GBKH,GBKL;
uint32_t offset;
uint8_t character[32]={0};
uint8_t* characterPtr;
GBKH=*code;
GBKL=*(code+1);
if(GBKH>0XFE||GBKH<0X81){
return;
}
GBKH-=0x81;
GBKL-=0x40;
//获取字符在bin文件中的偏移量,一个字符占(16*16)/8=32字节。
offset=((uint32_t)192*GBKH+GBKL)*32;
if((-1 ==fseek(fd,offset,SEEK_SET))){
printf("Fseek error\r\n");
}
//得到字符指针
fread(character,1,32,fd);
characterPtr = character;
//显示字符,16*16,一个字符占(16*16)/8=32字节。
int i,j;
for(j=0; j<16; j++){
for(i=0; i<16; i++){
if(*characterPtr &(0x80>>(i % 8))){
printf("*");
}else{
printf(" ");
}
if(i%8 == 7){
characterPtr++;
}
}
printf("\r\n");
}
}将以上程序保存为:fontTest.c,gcc编译,执行,结果如下图所示:
由执行结果可见,程序能够从二进制bin文件中提取有用信息,并且,该bin文件保存了GBK编码的所有汉字,将“你好”替换成其他任意汉字也是可从bin文件中提取出子模的,生成的bin文件是有效的。
接下来讲解程序中的几个注意事项:
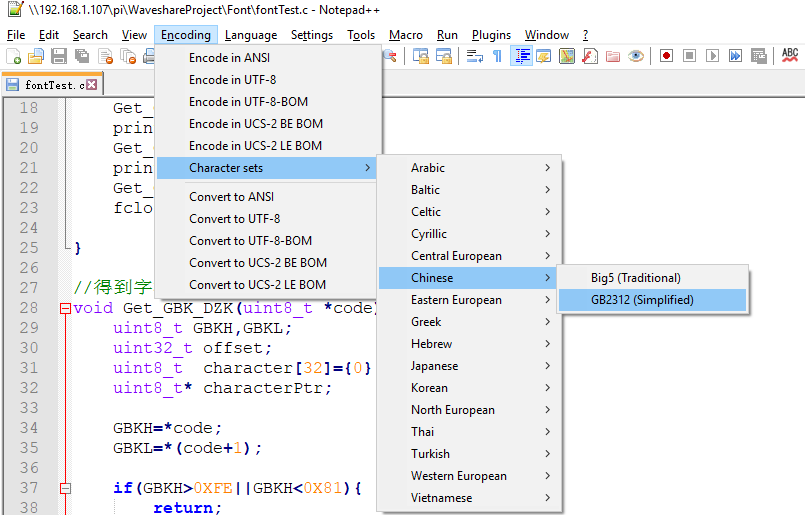
- 该程序源文件必须以GBK编码或GB2312编码保存(GBK编码兼容GB2312编码),在notepad++中,保存方式如下图所示:
- 解释下如何获得内存中字符的偏移量:
GBK编码:每个GBK码由2个字节组成:
第一个字节为0X81~0XF:
第二个字节分为两部分:
一是0X40-0X7E
二是0X80-0XFE
例如汉字“瑞”的GBK编码为C8 F0,第一字节C8,位于0X81-0XFE之间,第二字节F0,位于0X40-0XFE之间
第一个字节代表的意义称为区,那么GBK里面总共有126个区(0XFE-0X81+1=126)
第二个字节代表的意义就是每个区内有多少个汉字,算了一下,一共有190个(0XFE-0X80+0X7E-0X40+2=190)。
那么,GBK一共存储了126X190=23940个汉字。
仔细看GBK编码第二个字节两部分中,0X40-0X7E和0X80-0XFE,也就是说它是从0X40~到0XFF,中间的0x7F和最后的0xFF没有用到。
但是为了能够线性查找,我们暂且认为这两个字节也存在,就是我们强制把每个区190个汉字当做每个区192个汉字,不过0X7F和0XFF上没有汉字。
定义GBKH代表第一个字节,GBKL代表第二个字节,字库的偏移量offset,那么其计算方法如下:
GBKH=*code;
GBKL=*(code+1);
if(GBKH>0XFE||GBKH<0X81){
return;
}
GBKH-=0x81;
GBKL-=0x40;
//字模大小为16*16/8=32,一个字模占32字节
offset=((uint32_t)192*GBKH+GBKL)*32;实现了在控制台窗口打印汉字字模,那么在TFTLCD,OLED,墨水屏等屏幕上,只要先实现了画点功能,那么,显示任意汉字也可以实现的了。
5 任意汉字显示的实现(采用字库法)
最后再介绍一种显示汉字的方法,该方法采用Python实现,直接调用字体库,仅在Linux系统上可实现,下面将以树莓派为例,相关的操作如下:
首先安装好Pillow库以及必要液晶屏显示必要的SPI库,GPIO库等:
sudo apt-get install python3-pip
sudo apt-get install python-imaging
sudo pip3 install spidev
sudo pip3 install RPi.GPIO
sudo pip3 install Pillow安装 Pillow 如果报错: ImportError: libopenjp2.so.7: cannot open shared object file: No
such file or directory,则先执行如下指令:
sudo apt-get install libopenjp2-7-dev安装必要的字体:
sudo apt-get install ttf-wqy-zenhei ttf-wqy-microhei接下来是调用微软雅黑字体进行显示的部分示例(python3),详情代码参考文章末尾留下的Github:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import epd7in5b
import time
from PIL import Image,ImageDraw,ImageFont
import traceback
try:
epd = epd7in5b.EPD()
epd.init()
print("Clear...")
epd.Clear(0xFF)
# Drawing on the Horizontal image
HBlackimage = Image.new('1', (epd7in5b.EPD_WIDTH, epd7in5b.EPD_HEIGHT), 255)
HRedimage = Image.new('1', (epd7in5b.EPD_WIDTH, epd7in5b.EPD_HEIGHT), 255)
# Horizontal
print("Drawing")
drawblack = ImageDraw.Draw(HBlackimage)
drawred = ImageDraw.Draw(HRedimage)
font24 = ImageFont.truetype('/usr/share/fonts/truetype/wqy/wqy-microhei.ttc', 24)
drawblack.text((10, 0), 'hello world', font = font24, fill = 0)
drawblack.text((10, 20), '7.5inch e-Paper B', font = font24, fill = 0)
drawblack.text((150, 0), u'微雪电子', font = font24, fill = 0)
drawblack.line((20, 50, 70, 100), fill = 0)
drawblack.line((70, 50, 20, 100), fill = 0)
drawblack.rectangle((20, 50, 70, 100), outline = 0)
drawred.line((165, 50, 165, 100), fill = 0)
drawred.line((140, 75, 190, 75), fill = 0)
drawred.arc((140, 50, 190, 100), 0, 360, fill = 0)
drawred.rectangle((80, 50, 130, 100), fill = 0)
drawred.chord((200, 50, 250, 100), 0, 360, fill = 0)
epd.display(epd.getbuffer(HBlackimage), epd.getbuffer(HRedimage))
epd.sleep()
except:
print('traceback.format_exc():\n%s',traceback.format_exc())
exit()该代码的精髓在于,先创建一段缓存,然后采用pillow库的相关方法通过字符串获取对应字库中字符的字模,将字模数据存入缓存中,然后将缓存数据显示到屏幕上,详情参考pillow库中的Image,ImageDraw,ImageFont方法对应的手册。
注意,代码中的中文采用UTF-8编码,保存的时候,为防止乱码,必须以UTF-8编码保存(可采用notepad++工具保存为UTF-8编码)
最后,放出相关代码的Github:
软件工具,字模bin文件校验代码
刷屏代码示例



